In a distributed system, generating random ID values and avoiding conflicts is very important. The use of a primary key with the auto_increment attribute in a traditional database is no longer suitable, auto_increment does not work in a distributed environment because a single database server is not large enough and generating unique IDs across multiple databases with minimal delay is challenging.
Multiple options can be used to generate unique IDs in distributed systems. The options we considered are:
- Multi-master replication
- Universally unique identifiers
- Ticket servers
- Twitter Snowflake
Each option has its pros and cons. But, in this article, we will focus on Twitter Snowflake.
Twitter Snowflake
Twitter Snowflake is a distributed unique ID generator designed to generate unique IDs at a large scale. It is a 64-bit integer. I will show the layout of a 64-bit integer below.

Each section is explained below.
- Sign: 1 bit. It will always be 0. This is reserved for future uses. It can potentially be used to distinguish between signed and unsigned numbers.
- Timestamp: 41 bits. Milliseconds since the epoch or custom epoch.We use the default epoch is
1705743493982(at the time of writing this), equivalent to 2024-01-20 09:38:13 UTC - Datacenter ID: 5 bits, which gives us 2 ^ 5 = 32 datacenters.
- Machine ID: 5 bits, which gives us 2 ^ 5 = 32 machines per datacenter.
- Sequence number: 12 bits. For every ID generated on that machine/process, the sequence number is incremented by 1. The number is reset to 0 every millisecond.
Deep dive into Twitter Snowflake
In the high-level design, we discussed various options to design a unique ID generator in distributed systems. We settle on an approach that is based on the Twitter snowflake ID generator. Let us dive deep into the design. To refresh our memory, the design diagram is relisted below.
Datacenter IDs and machine IDs are chosen at the startup time, generally fixed once the system is up running. Any changes in datacenter IDs and machine IDs require careful review since an accidental change in those values can lead to ID conflicts. Timestamp and sequence numbers are generated when the ID generator is running.
Timestamp
The most important 41 bits make up the timestamp section. As timestamps grow with time, IDs are sortable by time. Image below shows an example of how binary representation is converted to UTC. You can also convert UTC back to binary representation using a similar method.
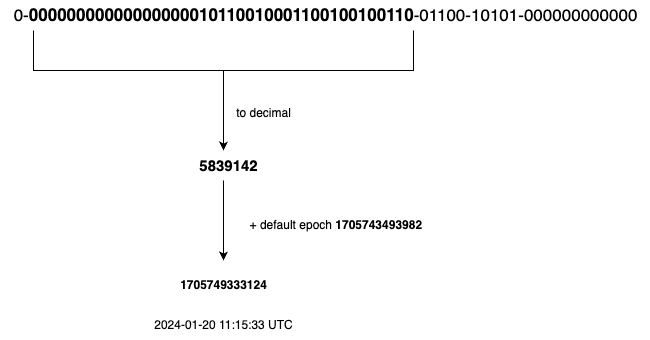
The maximum timestamp that can be represented in 41 bits is 2 ^ 41 - 1 = 2199023255551 milliseconds (ms), which gives us: ~ 69 years = 2199023255551 ms / 1000 seconds / 365 days / 24 hours/ 3600 seconds.
This means the ID generator will work for 69 years and having a custom epoch time close to today’s date delays the overflow time. After 69 years, we will need a new epoch time or adopt other techniques to migrate IDs.
Sequence number
Sequence number is 12 bits, which give us 2 ^ 12 = 4096 combinations. This field is 0 unless more than one ID is generated in a millisecond on the same server. In theory, a machine can support a maximum of 4096 new IDs per millisecond.